2-4: Measurement
 All research depends on measurement, but measuring psychological concepts like job satisfaction, leadership effectiveness, or organizational culture presents unique challenges that don’t exist in the physical sciences. You can’t just put a ruler next to someone’s motivation level or use a bathroom scale to weigh their job performance.
All research depends on measurement, but measuring psychological concepts like job satisfaction, leadership effectiveness, or organizational culture presents unique challenges that don’t exist in the physical sciences. You can’t just put a ruler next to someone’s motivation level or use a bathroom scale to weigh their job performance.
Measurement involves the assignment of numbers to objects or events in such a way as to represent specified attributes of the objects. When we ask “On a scale of one to ten, how do you feel about…” we’re trying to quantify subjective experiences using numerical scales.
Operational definitions are crucial for bridging the gap between abstract concepts and concrete measurement procedures. An operational definition defines a hypothetical construct in terms of the operations used to measure it. How exactly do you define “leadership effectiveness”? Through follower ratings of leader behavior? Achievement of team goals? 360-degree feedback scores? Career advancement rates? Each operational definition captures different aspects of the broader concept.
Attributes represent dimensions along which individuals can be measured and along which they vary. Measurement error encompasses things that can make measurement inaccurate. All measurement includes truth plus error — we make many measures so that this error will balance out over time and across items.
Measurement Attributes: Not All Numbers Are Equal
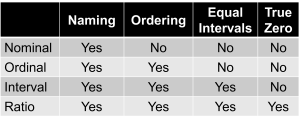
Numbers can contain up to four different attributes or types of information. Psychologist Stanley Smith Stevens developed the best-known classification with four levels, or scales, of measurement: nominal, ordinal, interval, and ratio (Stevens, 1946):
Nominal Measurement
Ability to name (nominal measurement) allows you to distinguish one thing from another — male/female, hourly/salary, different departments — but doesn’t imply any ordering.
Ordinal Measurement
Ability to put in order (ordinal measurement) enables rank-ordering — performance ratings from lowest to highest, preference rankings — but doesn’t assume equal intervals between ranks.
Interval Measurement
Equal intervals (interval measurement) mean that the difference between adjacent numbers represents the same amount of the measured attribute throughout the scale. The difference between test scores of 80 and 90 represents the same amount of knowledge as the difference between 90 and 100.
Ratio Measurement
True zero (ratio measurement) indicates that zero represents complete absence of the measured attribute. You can have zero sales or zero absences, but can you have zero leadership ability or zero job satisfaction?
Reliability and Validity: The Foundation of Good Measurement
Because of measurement error, we must carefully consider two important measurement concerns: reliability and validity. Reliability refers to the consistency of a measure, while validity refers to the extent to which a test measures what it is intended to measure (Anastasi & Urbina, 1997).

Reliability refers to the ability to measure the same thing over and over consistently. Validity refers to the ability to measure the construct you intended to measure rather than something else. Reliability and validity are generally measured using correlations, and all DVs have SOME reliability and validity — some measures are just better than others (Kaplan & Saccuzzo, 2017).
Here’s a crucial relationship: reliability is necessary but not sufficient for validity. You can have a perfectly reliable measure of something other than what you intended to measure. Imagine a “job satisfaction” survey that consistently measures general optimism instead of actual satisfaction with work. It would be reliable (consistent) but not valid for its intended purpose (Messick, 1995).
Types of Validity
Internal and External Validity
Internal and External Validity (which we discussed in the experimental section) have specific meanings in research design:
Internal validity refers to the extent to which we can draw causal inferences about variables. Are results due to the IV, or could other factors explain them? Higher internal validity comes from better control of confounding variables and is typically higher in lab studies.
External validity refers to the extent to which results obtained generalize to/across other people, settings, and times. Can we apply findings from student samples to employees? From lab tasks to real jobs? External validity is typically higher in field studies conducted in realistic settings.
The relationship between these concepts is important: Internal validity is to replication as external validity is to generalization. Good internal validity means you can probably replicate your findings. Good external validity means you can generalize your findings to other contexts.
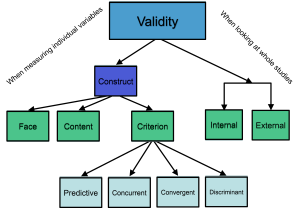
Construct Validity
Construct Validity refers to the extent to which a test (or DV) measures the underlying construct it was intended to measure. Hypothetical constructs are abstract qualities that are not directly observable and are difficult to measure — things like self-esteem, intelligence, cognitive ability, or self-control.
Three types of evidence are used to demonstrate construct validity:
Content validity refers to the degree to which a test covers a representative sample of the quality being assessed. This isn’t established in a quantitative sense but rather through expert judgment about whether the test items appropriately sample the domain of interest.
Criterion-related validity refers to the degree to which a test is a good predictor of attitudes, behavior, or performance. This comes in two forms:
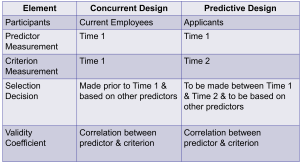
Predictive validity is the extent to which scores obtained at one point in time predict criteria at some later time. For example, do GREs, GPAs, and research experience predict success in graduate school?
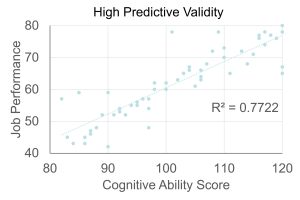
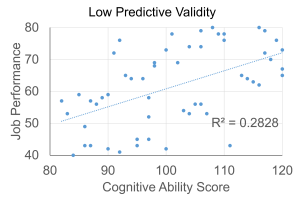
Concurrent validity is the extent to which a test predicts a criterion that is measured at the same time as the test. You might want to see if newly developed selection tests predict performance of current employees.
Face validity asks whether the test looks like it is measuring what it is intended to measure. One researcher submitted a journal article about a study of self-control using a video game. The editor noted that the game looks like it measures self-control (it has face validity), but then requested a follow-up study measuring performance on the game and other external measures of self-control to establish criterion-related validity.
Components of Criterion Validity
Components of Criterion Validity include:
Convergent validity demonstrates that your measure is related to other measures of similar constructs.
Divergent validity shows that your measure is not related to measures of dissimilar constructs.
These are demonstrated by using concurrent and/or predictive validity designs.
Types of Reliability
Reliability refers to the consistency or stability of a measure. It is imperative that a predictor be measured reliably because unsystematic measurement error renders a measure unreliable. We cannot predict attitudes, performance, or behaviors without reliable measurement — reliability sets a limit on validity (Schmidt & Hunter, 1996).
Test-Retest Reliability
Test-retest reliability reflects consistency of a test over time (also called a stability coefficient). You administer the test at time 1 and time 2 and see if individuals have a similar rank order at both administrations.
Parallel Forms Reliability
Parallel forms reliability measures the extent to which two independent forms of a test are similar measures of the same construct (coefficient of equivalence). Examples include two different forms of a final exam, comparing a survey on paper versus computer, or creating alternative test versions for disabled applicants.
Inter-Rater Reliability
 Inter-rater reliability measures the extent to which multiple raters or judges agree on ratings made about a person, thing, or behavior. You examine the correlation between ratings of two different judges rating the same person. This helps protect against interpersonal biases. If multiple people observe the same thing, they will inevitably “see” different things, but using multiple observers and averaging their responses makes it more likely to discover the “truth.”
Inter-rater reliability measures the extent to which multiple raters or judges agree on ratings made about a person, thing, or behavior. You examine the correlation between ratings of two different judges rating the same person. This helps protect against interpersonal biases. If multiple people observe the same thing, they will inevitably “see” different things, but using multiple observers and averaging their responses makes it more likely to discover the “truth.”
Internal Consistency Reliability
Internal consistency reliability provides an indication of the interrelatedness of items — it tells us how well items hang together to measure the same underlying construct.
Split-half reliability involves splitting the test in half by odd and even numbered questions and correlating the two halves.
Inter-item reliability looks at relationships among every item to test for consistency. Cronbach’s alpha (Cronbach, 1951) is the most common measure of internal consistency reliability.
Rule of thumb for reliability: The correlation (r) should be greater than .70 to be considered acceptable.
Media Attributions
- Measurement © Unknown is licensed under a Public Domain license
- Scales of Measurement © Jay Brown
- Reliability Related to Validity © Jay Brown
- Types of Validity © Jay Brown
- High Predictive Validity © Jay Brown
- Low Predictive Validity © Jay Brown
- Concurrent vs. Predictive Designs
- Judges Holding Up Their Scores © Unknown is licensed under a Public Domain license