4-2: Measurement, Again
 The Science Behind Measurement
The Science Behind Measurement
Why Reliability and Validity Matter (A Lot)
Here’s the thing about measurement in psychology — it’s way trickier than measuring physical things. You can’t put a ruler next to someone’s intelligence or weigh their motivation on a bathroom scale. All psychological measurement includes some error, which is why we obsess over reliability (consistency) and validity (accuracy) (Anastasi & Urbina, 1997).
Think of reliability and validity like shooting at a target. Reliability is consistently hitting the same spot — your shots are precise and repeatable. Validity is hitting the bullseye — your shots are accurate. You want both, but reliability without validity just means you’re consistently wrong.
Understanding Measurement Fundamentals
Measurement involves the assignment of numbers to objects or events in such a way as to represent specified attributes of the objects (Kaplan & Saccuzzo, 2017). When we ask someone to rate something “on a scale of one to ten,” we’re engaging in psychological measurement — attempting to quantify subjective experiences or characteristics.
Operational definitions become crucial in this process — they define hypothetical constructs in terms of the operations used to measure them (Pedhazur & Schmelkin, 1991). For example, we might operationally define “job performance” as supervisor ratings on specific behavioral dimensions, or “cognitive ability” as scores on a standardized intelligence test.
Attributes represent dimensions along which individuals can be measured and along which they vary. Understanding these attributes is essential because different measurement approaches are appropriate for different types of attributes.
Measurement error encompasses all the things that can make measurement inaccurate. The fundamental principle of psychological measurement is that all measurement includes truth plus error (Schmidt & Hunter, 1996). We make multiple measures specifically so that random errors will balance out and systematic errors can be identified and corrected.
Measurement Attributes and Scale Types
Not all numbers are equal — they contain different amounts of information depending on how they’re generated (Stevens, 1946):
- Nominal scales provide the ability to name (distinguish one category from another). Employee ID numbers or job categories represent nominal measurement.
- Ordinal scales add the ability to put observations in order. Performance rankings or Likert scale responses represent ordinal measurement.
- Interval scales include equal intervals between scale points. Temperature in Celsius or standardized test scores represent interval measurement.
- Ratio scales add a true zero point. Height, weight, and reaction times represent ratio measurement.
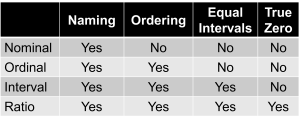
Understanding scale types matters because they determine what statistical analyses are appropriate and how results should be interpreted (Stevens, 1946). Higher-level scales contain more information and permit more sophisticated analyses.
Reliability: The Foundation of Good Measurement
Reliability refers to the consistency or stability of a measure (Nunnally & Bernstein, 1994). It is imperative that a predictor be measured reliably because unsystematic measurement error renders a measure unreliable. We cannot predict attitudes, performance, or behaviors without reliable measurement — reliability sets an upper limit to validity.
Types of Reliability: Different Ways to Check Consistency
Test-retest reliability reflects the consistency of a test over time, also known as the stability coefficient (Anastasi & Urbina, 1997). To assess test-retest reliability, we administer the same test at two different time points and examine whether individuals maintain similar rank orders at both occasions. High test-retest reliability is crucial for measuring stable traits like intelligence or personality that shouldn’t change dramatically over short periods.
For example, if someone scores in the 80th percentile on an intelligence test today, they should score similarly if tested again in a few weeks (assuming no major life changes or learning occurred). Low test-retest reliability might indicate that the test is measuring something unstable, contains too much measurement error, or is being influenced by situational factors.
Parallel forms reliability examines the extent to which two independent forms of a test are similar measures of the same construct, also called the coefficient of equivalence (Kaplan & Saccuzzo, 2017). This is like having two different versions of a final exam that should be equally difficult and measure the same knowledge, or comparing paper-and-pencil versus computer versions of a survey.
Parallel forms reliability is particularly important for high-stakes testing where test security matters, or when accommodations require different test formats. For example, tests designed for disabled applicants should show strong parallel forms reliability with standard versions to ensure fair assessment.
Inter-rater reliability measures the extent to which multiple raters or judges agree on ratings made about a person, thing, or behavior (Anastasi & Urbina, 1997). We examine the correlation between ratings of two different judges rating the same person or performance.
Inter-rater reliability helps protect against interpersonal biases because multiple people observing the same behavior will inevitably “see” different things based on their backgrounds, expectations, and attention. Using multiple observers and averaging their responses makes it more likely we’ll discover the “truth” about someone’s performance rather than one observer’s potentially biased perspective.
Internal consistency reliability indicates the interrelatedness of test items — essentially telling us how well items “hang together” to measure the same underlying construct (Nunnally & Bernstein, 1994).
Split-half reliability involves splitting a test in half (typically using odd and even numbered questions) and correlating the two halves. Inter-item reliability examines relationships among every item to test for consistency, typically measured using Cronbach’s alpha coefficient (Cronbach, 1951).
High internal consistency suggests that all items are measuring the same underlying characteristic, while low internal consistency might indicate that the test is measuring multiple different constructs or contains items that don’t belong together.
Validity: Are You Measuring What You Think You’re Measuring?
Validity represents the accuracy of measurement — the extent to which a test measures what it claims to measure (Messick, 1995). Within the context of predictors, criterion validity becomes critical to demonstrating that our assessments actually predict job performance.
Types of Validity Evidence
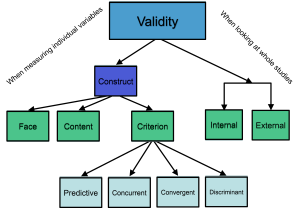
Construct validity addresses the fundamental question of whether a test actually measures the underlying psychological characteristic it was intended to measure (Messick, 1995). Are you really measuring emotional intelligence, or just general likability? Is your leadership assessment actually capturing leadership ability, or is it measuring charisma and communication skills instead?
Hypothetical constructs represent abstract qualities that are not directly observable and are difficult to measure, such as self-esteem, intelligence, or cognitive ability (Anastasi & Urbina, 1997). Because these constructs can’t be directly observed, we must infer their presence from observable behaviors, making construct validity particularly challenging and important.
Three types of evidence are used to demonstrate construct validity:
Content validity represents the degree to which a test covers a representative sample of the quality being assessed (Kaplan & Saccuzzo, 2017). Unlike other types of validity, content validity is not established in a quantitative sense but through expert judgment about whether test items adequately sample the domain of interest.
For example, a leadership test should include items covering various aspects of leadership (strategic thinking, people management, decision-making, communication) rather than focusing exclusively on one area like public speaking. Content validity ensures comprehensive coverage of the construct being measured.
Criterion-related validity measures the degree to which a test is a good predictor of attitudes, behavior, or performance (Anastasi & Urbina, 1997). This type of validity is indicated by the correlation between predictor and criterion, and these correlations are called validity coefficients in selection contexts.
The coefficient of determination (r²) represents the percentage of variance in the criterion accounted for by the predictor. For example, if cognitive ability correlates .50 with job performance, the coefficient of determination is .25, meaning cognitive ability explains 25% of the variance in job performance.
Face validity asks whether the test looks like it is measuring what it is intended to measure (Anastasi & Urbina, 1997). While not a true form of validity evidence, face validity affects test-taker motivation and organizational acceptance of assessment programs.
Approaches to Criterion-Related Validity
Predictive validity represents the extent to which scores obtained at one point in time predict criteria measured at some later time (Anastasi & Urbina, 1997). This is the gold standard for selection validity — collect predictor data during hiring, then see how people perform months or years later on the job.
For example, we might examine whether GREs, GPAs, and research experience predict success in graduate school by following students through their programs and correlating admission data with later performance measures.
Predictive validity studies follow a specific process:
- Gather predictor data on all applicants
- Hire some applicants based on predictors that are NOT part of the validation study (to ensure a full range of predictor scores among those hired)
- After sufficient time on the job, gather performance data as criteria
- Compute validity coefficients between predictor and criterion scores
Concurrent validity examines the extent to which a test predicts a criterion that is measured at the same time as the test (Kaplan & Saccuzzo, 2017). This approach is often used when organizations want to examine whether newly developed selection tests predict the performance of current employees.
In concurrent validation, both predictor and criterion data are collected from incumbent employees simultaneously, and validity coefficients are computed between predictor and criterion scores.
While concurrent validity is more practical and faster than predictive validity, it has limitations. Current employees may differ from job applicants in motivation, ability range, or other characteristics that could affect the predictor-criterion relationship.
Components of Criterion Validity
Convergent validity demonstrates that a measure is related to other measures of similar constructs (Messick, 1995). If you develop a new creativity test, it should correlate positively with existing creativity measures.
Divergent validity shows that a measure is not related to measures of dissimilar constructs (Messick, 1995). Your creativity test should not correlate highly with measures of unrelated characteristics like physical strength or color vision.
Both convergent and divergent validity can be demonstrated using concurrent and/or predictive validity designs, providing comprehensive evidence about what a test does and doesn’t measure.
The Relationship Between Reliability and Validity
Reliability and validity are intimately connected — reliability sets an upper limit for validity (Nunnally & Bernstein, 1994). You cannot have a valid measure that is unreliable, but you can have a reliable measure that lacks validity.
Think of it this way: if a test produces inconsistent results (low reliability), it cannot consistently predict anything else (low validity). However, a test might consistently measure the wrong thing (high reliability, low validity).
This relationship explains why reliability analysis always comes before validity analysis in test development and evaluation (Anastasi & Urbina, 1997). There’s no point in examining whether an unreliable test predicts job performance because unreliable tests can’t predict anything consistently.
Internal and External Validity in Research
Internal validity refers to the extent to which we can draw causal inferences about variables — are results actually due to the independent variable we’re studying? (Pedhazur & Schmelkin, 1991). High internal validity requires careful control of extraneous variables and is typically higher in laboratory studies where conditions can be precisely managed.
External validity concerns the extent to which results generalize across other people, settings, and times (Pedhazur & Schmelkin, 1991). Can we generalize findings from student samples to employees? Do results from one industry apply to others? External validity is typically higher in field studies conducted in realistic work environments.
There’s often a tradeoff between internal and external validity. Laboratory studies that maximize control (high internal validity) may use artificial tasks or college student participants that limit generalizability (low external validity). Field studies conducted in actual workplaces may have high external validity but less control over confounding variables (potentially lower internal validity).
Understanding this tradeoff helps us interpret research findings appropriately and design studies that balance scientific rigor with practical relevance (Pedhazur & Schmelkin, 1991).
Practical Implications of Measurement Quality
The quality of measurement directly affects all subsequent decisions based on that measurement (Schmidt & Hunter, 1996). Poor reliability and validity in selection predictors lead to:
- Hiring mistakes — selecting candidates who fail or rejecting those who would succeed
- Legal vulnerabilities — using tests that can’t be shown to predict job performance
- Wasted resources — time and money spent on ineffective assessment procedures
- Unfair treatment — inconsistent or biased evaluation of candidates
Conversely, high-quality measurement enables organizations to:
- Make better hiring decisions that improve performance and reduce turnover
- Defend selection practices against legal challenges
- Use resources efficiently by focusing on effective predictors
- Treat candidates fairly through consistent, job-related assessment
The investment required to develop or purchase high-quality measurement instruments typically pays for itself through improved decision-making and reduced costs associated with hiring mistakes (Kaplan & Saccuzzo, 2017).
Media Attributions
- Measurement © Dpatel0546 is licensed under a CC BY-SA (Attribution ShareAlike) license
- Scales of Measurement © Jay Brown
- Types of Validity © Jay Brown
{kind=link}